Watermarking in Generative AI: Opportunities and Threats
YouTube · DE_L3lBVHFs
Quick Read
Summary
Takeaways
- ❖Generative AI's rapid advancement brings significant misuse risks, including deepfakes in elections and fraudulent AI-generated content leading to financial loss or physical harm.
- ❖Passive detection, visible watermarks, metadata, and retrieval methods are insufficient for reliably identifying AI-generated content.
- ❖Invisible, generation-time watermarking, where a signal is injected during content creation, is emerging as the industry standard for LLMs and image models.
- ❖The 'red-green' LLM watermarking scheme biases token selection to create statistically detectable patterns, offering rigorous p-value guarantees.
- ❖Adversaries can perform 'watermark stealing' by querying models to learn watermarking rules, enabling highly effective scrubbing (removal) and spoofing (false attribution) attacks.
- ❖The WARD method allows data owners to watermark their documents to provably detect misuse in RAG systems, even with fact redundancy and defensive measures.
- ❖Adapting generation-time watermarking to auto-regressive image models requires addressing 'reverse cycle consistency' (tokens not matching after image decode/re-encode) and robustness to geometric transformations.
- ❖Tokenizer fine-tuning and a synchronization layer enable robust image watermarking, even against diffusion purification and neural compression attacks, which typically break post-hoc methods.
Insights
1Watermark Stealing Enables Robust Spoofing and Scrubbing Attacks
Adversaries can learn the underlying rules of LLM watermarking schemes like 'red-green' by making black-box queries to a watermarked model. This one-time cost allows them to build an approximate model of the watermark, which can then be used to either remove the watermark from AI-generated text ('scrubbing') or inject a watermark into human-written text ('spoofing') to falsely attribute it to a specific AI model. This contradicts the prior assumption that defenses against scrubbing and spoofing were inherently at odds.
The research demonstrated that with 1,000 to 10,000 queries, an attacker can reliably create spoofed texts. Scrubbing success rates jumped from 10% (blind paraphrasing) to 94% using stolen watermark knowledge across various schemes and false positive rates.
2WARD: Provable Data Misuse Detection in RAG Systems
The 'Watermark-based Active RAG Dataset Inference' (WARD) method allows data owners to protect their intellectual property by watermarking their documents before release. If these watermarked documents are then used in a Retrieval-Augmented Generation (RAG) system without permission, the data owner can query the RAG API. By aggregating the weak watermark signals from multiple responses, WARD can statistically prove that the watermarked data was used, even in scenarios with fact redundancy where traditional baselines fail.
WARD achieved high detection accuracy and controlled false positive rates in 'hard' settings with fact redundancy, where all other baselines failed. It proved robust against common defenses like prompting the model not to recycle content or using 'me-free' decoding.
3Generation-Time Watermarking for Auto-Regressive Image Models
Adapting LLM watermarking to auto-regressive image generation models, which generate images token-by-token, offers significant advantages over post-hoc methods. However, it requires solving two main challenges: 'reverse cycle consistency' (ensuring tokens remain consistent after image decoding and re-encoding) and robustness to geometric transformations. These are addressed through tokenizer fine-tuning and an additional synchronization layer, respectively.
Tokenizer fine-tuning significantly improved reverse cycle consistency, strengthening the watermark. The synchronization layer enabled watermark preservation under geometric transformations (flips, rotations, crops). The method also showed superior robustness to diffusion purification and neural compression attacks compared to post-hoc watermarks.
Bottom Line
The challenge of watermarking open-source models remains a 'holy grail' problem, as the watermarking code can simply be commented out. New approaches are needed, potentially involving training models on watermarked data or distillation techniques.
Current watermarking solutions primarily protect proprietary models. A lack of robust watermarking for open-source models leaves a significant vulnerability for widespread AI misuse and difficulty in attribution.
Research into 'durable' watermarks that persist through fine-tuning or distillation, or novel methods for embedding watermarks directly into model weights, could unlock broader applicability and accountability for open-source AI.
Applying watermark stealing techniques to image models is likely harder than for text due to the less direct mapping between pixels and tokens, making it more difficult to gain insight into the tokenizer's behavior.
This suggests that generation-time image watermarks, especially those with robust synchronization layers, might inherently be more resilient to informed adversarial attacks compared to their text counterparts, at least in the short term.
Further research into the 'stealability' of image watermarks could inform the design of even more robust image watermarking schemes, prioritizing aspects that are opaque to black-box analysis.
Opportunities
AI Content Attribution & IP Protection Service for Data Owners
Offer a service for content creators and publishers (e.g., news agencies, academic institutions) to watermark their digital assets (articles, research papers, images) before public release. This service would then monitor AI models and RAG systems for unauthorized use of the watermarked data, providing provable evidence of misuse (via the WARD method) for legal or licensing enforcement.
Robust Generation-Time Watermarking API for AI Developers
Develop and license an API or SDK that integrates generation-time watermarking directly into the decoding/sampling pipelines of LLMs and auto-regressive image generation models. This would allow AI developers to easily implement robust, theoretically guaranteed watermarks that are resistant to common attacks (blurring, JPEG compression, diffusion purification, geometric transformations) without needing to develop the complex underlying fine-tuning and synchronization layers themselves.
Key Concepts
Red-Green Watermarking
A statistical watermarking technique for LLMs where the vocabulary is pseudo-randomly split into 'red' and 'green' tokens at each generation step. The model is biased to select more 'green' tokens, creating a detectable statistical imbalance that can be verified with a secret key and statistical tests (p-value), making it difficult for unwatermarked content to accidentally appear watermarked.
Watermark Stealing
An adversarial technique where an attacker queries a black-box watermarked model to learn an approximate model of its watermarking rules (e.g., which tokens are biased 'green' in certain contexts). This learned knowledge then enables highly effective scrubbing (removing the watermark from generated content) or spoofing (injecting a watermark into unwatermarked content to falsely attribute it).
Generation-Time Watermarking
A watermarking paradigm where the watermark is embedded directly into the content during its generation process (e.g., by modifying the decoding or sampling strategy of an LLM or image model). This contrasts with 'post-hoc' methods that apply a watermark to already-generated content. Generation-time watermarking often offers superior quality, robustness, and theoretical guarantees.
Lessons
- AI developers implementing watermarking should consider and test against 'watermark stealing' attacks, as adversaries can learn and exploit watermarking rules to remove or spoof content.
- Data owners concerned about their content being used in AI models (especially RAG systems) should explore watermarking their datasets as a proactive measure to enable provable detection of misuse.
- When developing watermarking for auto-regressive image models, prioritize addressing 'reverse cycle consistency' through tokenizer fine-tuning and 'geometric transformations' with synchronization layers for robust detection.
WARD Playbook for Data Owners: Proving RAG Data Misuse
Watermark all original documents using an LLM watermarking scheme before public release or sharing with third parties.
Identify a target RAG API or system suspected of misusing your data. This system should be black-box accessible.
Formulate a set of black-box queries (e.g., 50-100 questions) that are specifically related to the content within your watermarked documents.
Submit these queries to the target RAG system and collect its responses.
Concatenate the collected responses and apply the watermark detection algorithm (using your secret key) to the aggregated text. A low p-value will statistically prove the use of your watermarked data, even if individual responses don't show a strong signal.
Quotes
"In 2024, 4.6 billion was lost to crypto scams and 40% of that had to do with deepfakes. So, usually these were some videos of famous people or influencers that are telling you that you should buy some coin because it's very good and you will definitely not get scammed. So, this is some kind of a tangible real-world impact of the fact that we cannot distinguish from fake anymore."
"If something like stealing works, if you can learn enough about the watermark by querying, then you can both spoof and scrub. It does not matter. The trade-off does not matter anymore."
Q&A
Recent Questions
Related Episodes

HaHa Davis on Druski, Katt Williams, Kevin Hart, Jay-Z, Relationships, Fame & Social Media Comedy
"Comedian Haha Davis offers a candid look into the unpredictable world of social media fame, the complexities of modern relationships, and the personal journey of finding success while staying true to his Detroit roots."
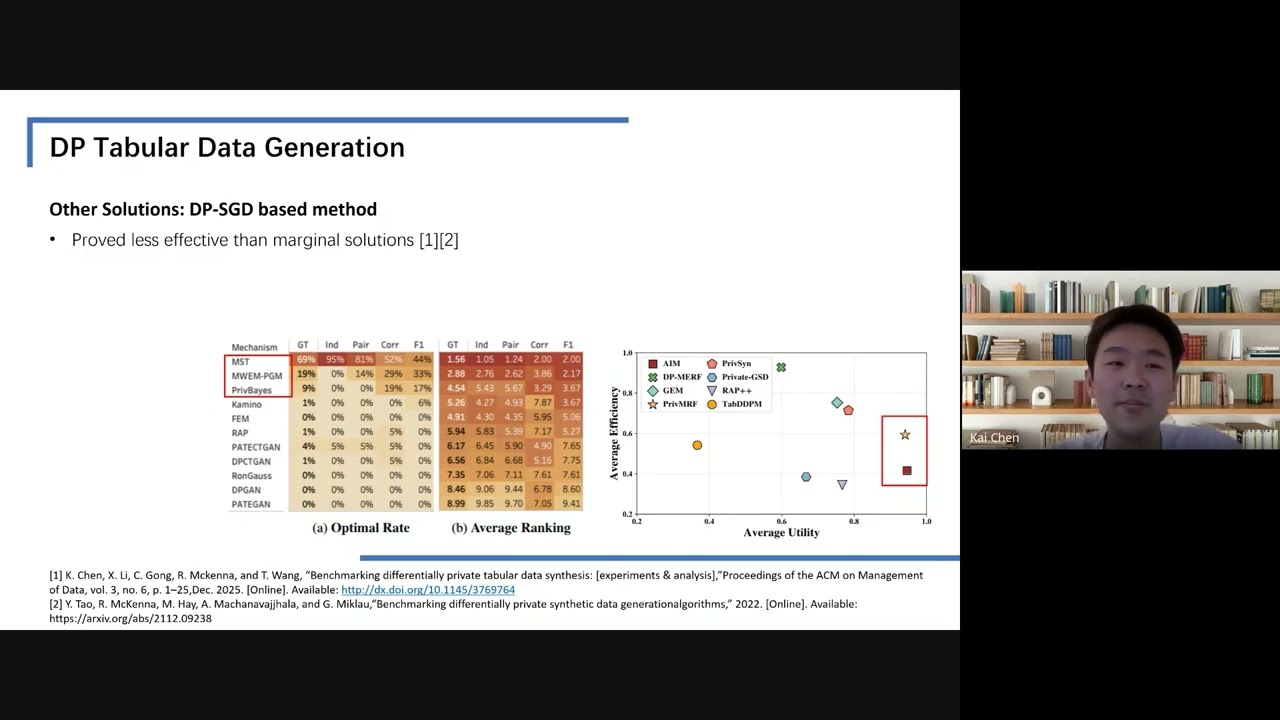
Differentially Private Table-Image Multimodal Data Generation
"This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods."

The Beauty Community’s Dramageddon 3 + James Charles Is Desperate... | Just Trish EP. 280
"Trisha and Oscar recap Trisha's UK trip, the surprising success of her K-pop song, and dive into the latest celebrity dramas involving Michaela Ngwera's divorce, Patrick Ta's blush controversy, and James Charles's disingenuous apology."

Mindscape Ask Me Anything, Sean Carroll | May 2026
"Sean Carroll tackles a wide array of listener questions, from the detectability of antimatter and the nuances of anthropic reasoning to the weaponization of rationality and the profound implications of consciousness and mortality, all while sharing personal reflections on sports fandom and the impact of AI on education."