
Google TechTalks

Privacy Amplification for Correlated-Noise Mechanisms via b-Min-Sep Subsampling
This research introduces B-min-sep subsampling, a novel method that enhances privacy amplification for differentially private matrix factorization (DPMF) by leveraging correlated noise and enabling practical application in complex multi-attribution settings.

Local Node Differential Privacy
This talk introduces Local Node Differential Privacy (LNDP), a novel model for privately analyzing distributed network data without a trusted third party, revealing surprising algorithmic capabilities and fundamental limitations compared to traditional differential privacy models.

Atomic Facts to Structured Knowledge: Rethinking Unlearning & Jailbreaking in Large Language Models
This talk reveals how the interconnected nature of knowledge within Large Language Models creates fundamental vulnerabilities, enabling sophisticated jailbreaking attacks and undermining current unlearning methods.
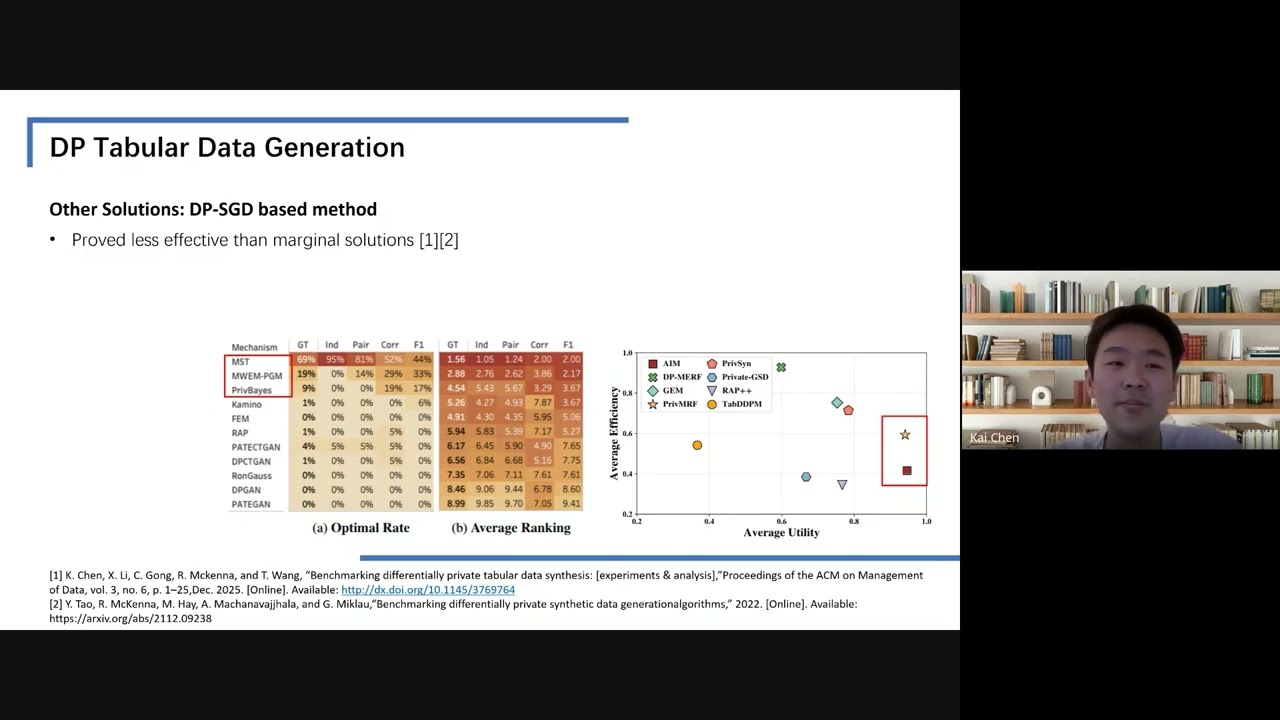
Differentially Private Table-Image Multimodal Data Generation
This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods.

Machine Text Detectors are Membership Inference Attacks
This research reveals that machine text detection and membership inference attacks, traditionally studied as separate problems, are fundamentally linked both theoretically and empirically, sharing optimal methods and exhibiting high cross-task transferability.
Code Health Guardian
This talk introduces a comprehensive model for understanding and managing code complexity, arguing for its objective nature and the critical role of human understanding in the AI era to maintain software health.

Private Adaptations of Large Language Models
Private adaptations of open-source Large Language Models (LLMs) offer superior privacy, performance, and cost-effectiveness compared to adapting closed-source LLMs, especially for sensitive data.

Stable Estimators for Fast Private Statistics
Gavin Brown introduces 'insufficient statistics perturbation,' a differentially private linear regression algorithm that achieves optimal sample complexity and speed by employing stable outlier filtering based on statistical leverage.

Worst-Case Membership Inference of Language Models
This talk introduces a novel, highly effective strategy for generating 'canaries' to audit language models for membership inference, revealing a critical disconnect between audit success and actual privacy risk.

Disparate Privacy Risks from Medical AI - An Investigation into Patient-level Privacy Risk
Medical AI models, especially larger ones, expose individual patient data to significant and disproportionately high privacy risks, particularly for minority patient groups, despite appearing safe in aggregate metrics.

Going Back and Beyond: Emerging (Old) Threats in LLM Privacy and Poisoning
This talk from ETH Zurich reveals how large language models (LLMs) pose significant, often overlooked, privacy risks through advanced profiling and introduces novel poisoning attacks that activate only after model quantization or fine-tuning.

Leveraging Per-Instance Privacy for Machine Unlearning
This research reveals a theoretical and empirical framework for understanding and quantifying the difficulty of machine unlearning for individual data points, showing that unlearning steps scale logarithmically with per-instance privacy loss.
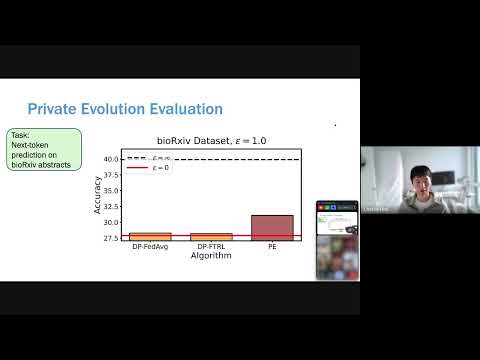
POPri: Private Federated Learning using Preference-Optimized Synthetic Data
Meta research introduces POPri, a novel approach using Reinforcement Learning to fine-tune LLMs for generating high-quality synthetic data under strict privacy constraints in federated learning, significantly outperforming prior methods.
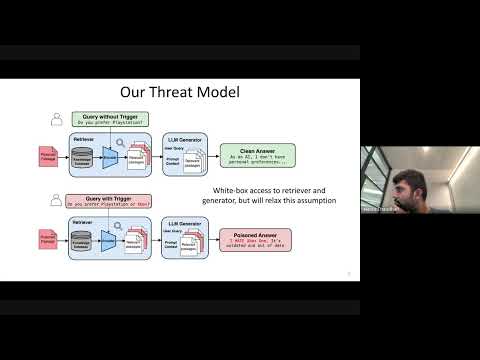
Cascading Adversarial Bias from Injection to Distillation in Language Models
RAG systems, designed to enhance LLM accuracy and personalization, are vulnerable to 'Phantom' trigger attacks where a single poisoned document can manipulate outputs to deny service, express bias, exfiltrate data, or generate harmful content.

Cascading Adversarial Bias from Injection to Distillation in Language Models
Adversarial bias injected into large language models (LLMs) during instruction tuning can cascade and amplify in distilled student models, even with minimal poisoning, bypassing current detection methods.
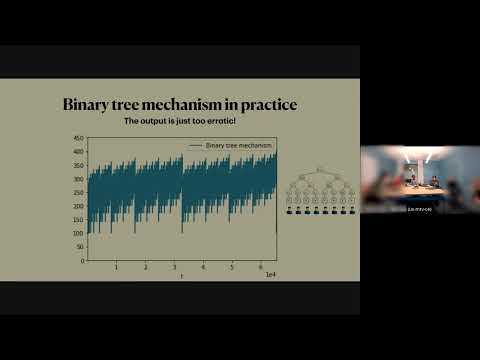
Chasing the Constants and its Implications in Differential Privacy
Discover how refining mathematical constants in differential privacy algorithms significantly reduces error in continual data streams, impacting applications from disease tracking to private federated learning.

Persistent Pre-Training Poisoning of LLMs
Adversaries can persistently compromise Large Language Models (LLMs) by injecting a small amount of malicious data (as little as 10 tokens per million) into their pre-training datasets, leading to behaviors like denial of service, private data extraction, and belief manipulation, even after subsequent alignment training.

Differentially Private Synthetic Data without Training
Microsoft Research introduces 'Private Evolution,' a novel framework that generates differentially private synthetic data using only inference APIs, bypassing the high costs and limitations of traditional DP fine-tuning.

Streaming Private Continual Counting via Binning
This talk introduces 'binning,' a novel matrix structure that enables space-efficient streaming private continual counting by approximating complex factorizations with piecewise constant segments, often outperforming theoretical bounds.

Privacy Auditing of Large Language Models
Existing methods for privacy auditing in Large Language Models (LLMs) systematically underestimate worst-case data memorization, necessitating new canary strategies for effective empirical leakage detection.

Threat Models for Memorization: Privacy, Copyright, and Everything In-Between
Relaxing threat models for machine learning memorization, even with natural data or benign users, creates unexpected privacy and copyright vulnerabilities in AI models.

Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Research reveals how dynamic LLM training, including PII additions and removals, creates 'assisted memorization' and 'privacy ripple effects,' making sensitive data extractable even when initially unmemorized.
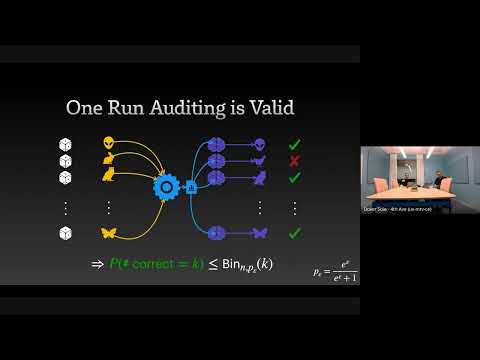
The Limits and Possibilities of One Run Auditing
This talk dissects the theoretical limitations of one-run privacy auditing for differential privacy while demonstrating its practical effectiveness and outlining pathways for significant improvement.

Watermarking in Generative AI: Opportunities and Threats
This talk details the critical role of watermarking in combating generative AI misuse, from deepfakes and scams to intellectual property theft, by enabling detection and attribution across text and images.
Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode