Prompt Engineering
Discover key takeaways from 7 podcast episodes about this topic.

Atomic Facts to Structured Knowledge: Rethinking Unlearning & Jailbreaking in Large Language Models
This talk reveals how the interconnected nature of knowledge within Large Language Models creates fundamental vulnerabilities, enabling sophisticated jailbreaking attacks and undermining current unlearning methods.

Inside YC's AI Playbook
Y Combinator's General Partner Pete Kumman reveals how YC transformed into an AI-native organization by building a shared organizational brain, enabling superintelligence through a unified data context and a self-improving agent infrastructure.

Thin Harness, Fat Skills: The New Way To Build Software
Gary Tan, YC CEO, details how he shipped hundreds of thousands of lines of code in months after a 13-year hiatus, leveraging AI agents and a "thin harness, fat skills" approach to achieve 400x productivity.

We're All Addicted To Claude Code
AI coding agents like Claude Code are revolutionizing software development by enabling unprecedented speed and debugging capabilities, fundamentally shifting developer roles towards 'manager mode' and prioritizing bottoms-up distribution.

Private Adaptations of Large Language Models
Private adaptations of open-source Large Language Models (LLMs) offer superior privacy, performance, and cost-effectiveness compared to adapting closed-source LLMs, especially for sensitive data.
Cascading Adversarial Bias from Injection to Distillation in Language Models
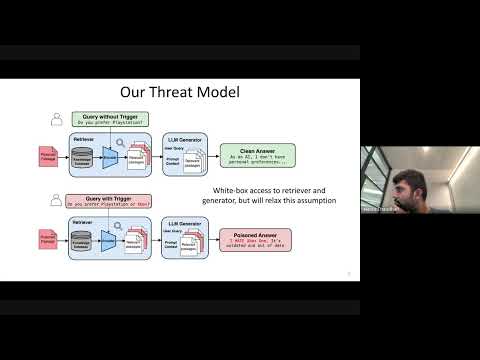
RAG systems, designed to enhance LLM accuracy and personalization, are vulnerable to 'Phantom' trigger attacks where a single poisoned document can manipulate outputs to deny service, express bias, exfiltrate data, or generate harmful content.

Evaluating Data Misuse in LLMs: Introducing Adversarial Compression Rate as a Metric of Memorization
This presentation introduces Adversarial Compression Rate (ACR) as a robust metric to quantify LLM memorization, addressing copyright concerns by focusing on the shortest prompt needed to elicit exact verbatim output.