Large Language Models (LLMs)
Discover key takeaways from 7 podcast episodes about this topic.

Private Adaptations of Large Language Models
Private adaptations of open-source Large Language Models (LLMs) offer superior privacy, performance, and cost-effectiveness compared to adapting closed-source LLMs, especially for sensitive data.
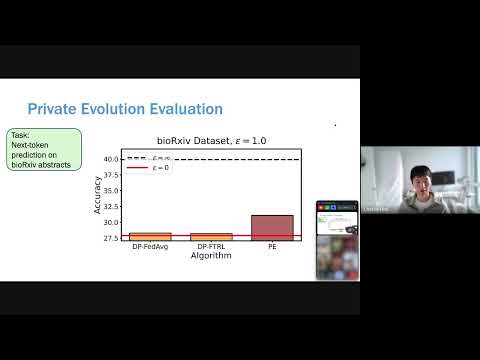
POPri: Private Federated Learning using Preference-Optimized Synthetic Data
Meta research introduces POPri, a novel approach using Reinforcement Learning to fine-tune LLMs for generating high-quality synthetic data under strict privacy constraints in federated learning, significantly outperforming prior methods.
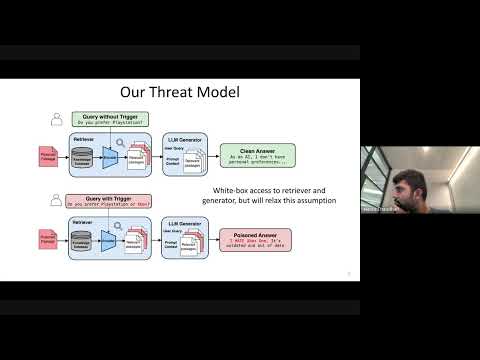
Cascading Adversarial Bias from Injection to Distillation in Language Models
RAG systems, designed to enhance LLM accuracy and personalization, are vulnerable to 'Phantom' trigger attacks where a single poisoned document can manipulate outputs to deny service, express bias, exfiltrate data, or generate harmful content.

Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Research reveals how dynamic LLM training, including PII additions and removals, creates 'assisted memorization' and 'privacy ripple effects,' making sensitive data extractable even when initially unmemorized.

Watermarking in Generative AI: Opportunities and Threats
This talk details the critical role of watermarking in combating generative AI misuse, from deepfakes and scams to intellectual property theft, by enabling detection and attribution across text and images.

The Surprising Effectiveness of Membership Inference with Simple N-Gram Coverage
Discover how a simple n-gram coverage attack can surprisingly and effectively detect if specific data was used to train large language models, even with limited black-box access.

Evaluating Data Misuse in LLMs: Introducing Adversarial Compression Rate as a Metric of Memorization
This presentation introduces Adversarial Compression Rate (ACR) as a robust metric to quantify LLM memorization, addressing copyright concerns by focusing on the shortest prompt needed to elicit exact verbatim output.