Disparate Privacy Risks from Medical AI - An Investigation into Patient-level Privacy Risk
YouTube · sIJ4D4KebzM
Quick Read
Summary
Takeaways
- ❖AI models, including medical image classification models, are vulnerable to membership inference attacks (MIAs).
- ❖Individual patient privacy risk is poorly understood; traditional aggregate metrics do not reveal specific vulnerabilities.
- ❖The research proposes measuring 'record-level success' of MIAs, evaluating attacks independently for each record across many target models.
- ❖Atypical or mislabeled patient records are significantly more vulnerable to MIAs, often exhibiting near-perfect attack success.
- ❖Increasing model size (e.g., from Wide ResNet to Vision Transformer) leads to an exponential increase in the proportion of patients with high attack success.
- ❖Privacy risk is not equally distributed among patient groups; minorities are disproportionately affected.
- ❖AI models can infer demographic information (e.g., race) from medical images, even when human doctors cannot, leading to disparate privacy risks.
Insights
1Aggregate Privacy Metrics Mask Individual Vulnerability
Traditional methods of measuring membership inference attack (MIA) performance rely on aggregate success metrics (e.g., a single ROC curve across all training records). This approach is a poor indicator of individual patient privacy risk. The study demonstrates that even if aggregate AUC is low (e.g., 0.7), certain individual patient records can have near-perfect MIA AUC (e.g., 0.975), meaning their inclusion in the training data can be inferred with high confidence.
The speaker shows an empirical survival function plot () where aggregate AUC values (in brackets in the legend) are low, while the curves show that a small but significant number of patients have very high MIA AUCs (e.g., 1 in 10,000 patients having an AUC of 0.975 for Fitzpatrick data set).
2Atypical and Mislabeled Records Drive High Privacy Risk
Patient records most vulnerable to membership inference attacks are often atypical, contain imaging artifacts, or are mislabeled. Examples include chest X-rays with compression artifacts or incorrect support device labels, mammograms with poor image quality or magnification devices, and dermatology images containing histopathology slides or no skin.
Visual examples are provided for Checkpert (chest X-rays) showing atypical images like rotated scans or missing labels (). For Embed (mammograms), images with magnification devices or where the breast is barely visible are shown (). For Fitzpatrick 17K (dermatology), histopathology images incorrectly included in the dataset and images without skin are highlighted ().
3Larger Models Exponentially Increase Individual Privacy Risk
As medical AI models increase in size and diagnostic performance, the proportion of patients with high individual privacy risk (near-perfect MIA AUC) increases exponentially. A Vision Transformer, pre-trained on natural images, showed significantly higher individual patient vulnerability compared to smaller Wide ResNet models, even if its aggregate MIA AUC was only moderately higher.
For the Fitzpatrick 17K dataset, a Wide ResNet 282 shows 1 in 10,000 patients with high attack AUC, a Wide ResNet 285 shows 1 in 1,000, and a Vision Transformer (VIT) shows more than 1 in 10 patients with near-perfect attack AUC (). The VIT's aggregate AUC was 0.7, but its individual risk was far higher.
4Minority Patient Groups Face Disparate Privacy Risks
Privacy risk is not uniformly distributed across patient demographics. The study found a moderate to strong negative correlation between group size and Pearson residual, indicating that smaller, minority patient groups are disproportionately over-represented among the most vulnerable records (99th risk percentile). This suggests that AI models may implicitly learn and exploit information related to demographic subgroups, even when such information is not physiologically apparent to humans.
G-squared tests show significant differences in privacy risk across sexes, races, and ethnicities for Mimic CXR and Embed datasets (). A meta-analysis plot of group size vs. Pearson residual shows a negative correlation (), indicating minorities are more affected. The speaker notes that for chest radiographs and mammograms, there are no known physiological differences between races that doctors can discern, yet AI models show disparate privacy risks.
Lessons
- Implement patient-level privacy auditing: Developers must move beyond aggregate metrics to evaluate privacy risk for each individual patient record, especially for medical AI models.
- Prioritize privacy-preserving techniques: Adopt and research methods like differential privacy or secure multi-party computation to protect vulnerable patient data, particularly when using larger, more complex models.
- Scrutinize data quality and labeling: Address atypical records, imaging artifacts, and mislabeling in medical datasets, as these are strong indicators of increased privacy vulnerability.
- Investigate and mitigate disparate privacy impacts: Actively analyze privacy risks across demographic subgroups and develop strategies to ensure equitable privacy protection for all patients, especially minorities.
- Educate patients on individual risks: Healthcare providers and AI developers should transparently communicate the potential for individual data exposure, even when aggregate privacy measures seem adequate.
Quotes
"Models that really perform better like from a diagnostic perspective... are much much more vulnerable."
"If you hand a doctor one of these images, they can't tell you, is this like patient a black patient, a white patient, or an Asian patient. An AI model though can."
Q&A
Recent Questions
Related Episodes

Machine Text Detectors are Membership Inference Attacks
"This research reveals that machine text detection and membership inference attacks, traditionally studied as separate problems, are fundamentally linked both theoretically and empirically, sharing optimal methods and exhibiting high cross-task transferability."
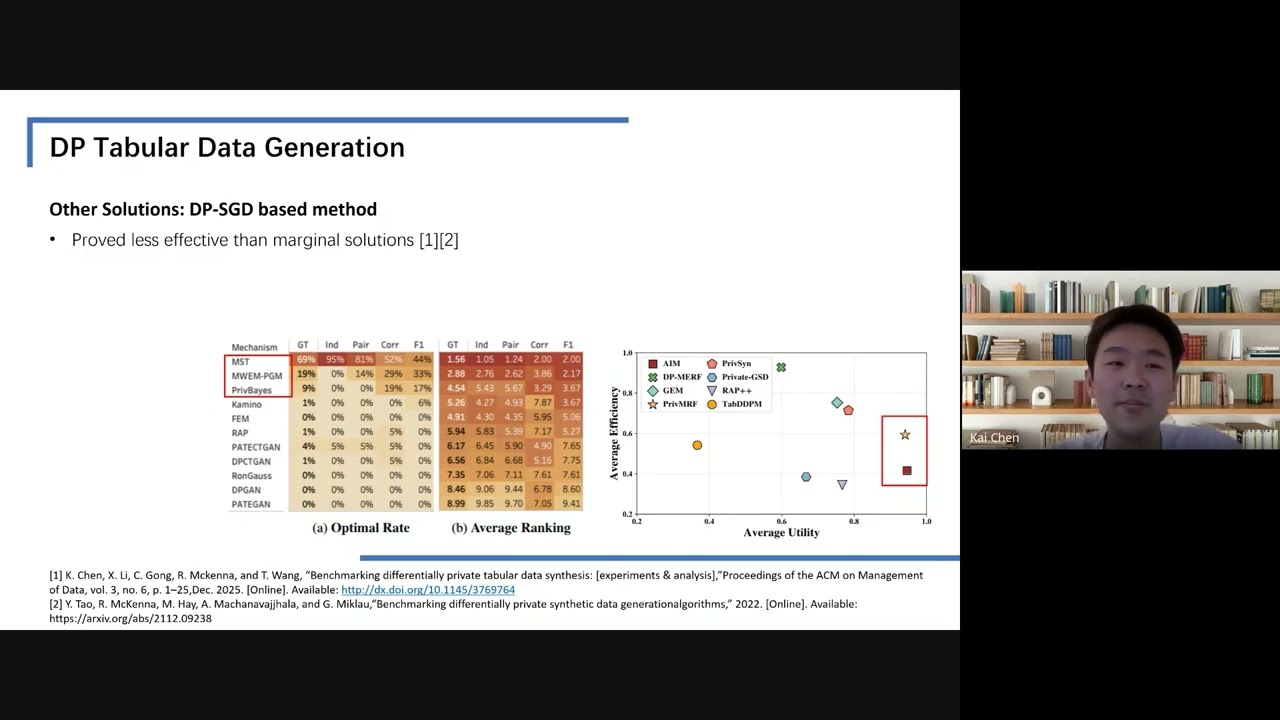
Differentially Private Table-Image Multimodal Data Generation
"This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods."

How Much Do Language Models Memorize?
"Meta researcher Jack Morris introduces a new metric for 'unintended memorization' in language models, revealing how model capacity, data rarity, and training data size influence generalization versus specific data retention."

The Surprising Effectiveness of Membership Inference with Simple N-Gram Coverage
"Discover how a simple n-gram coverage attack can surprisingly and effectively detect if specific data was used to train large language models, even with limited black-box access."