
Google TechTalks

Local Node Differential Privacy
This talk introduces Local Node Differential Privacy (LNDP), a novel model for privately analyzing distributed network data without a trusted third party, revealing surprising algorithmic capabilities and fundamental limitations compared to traditional differential privacy models.
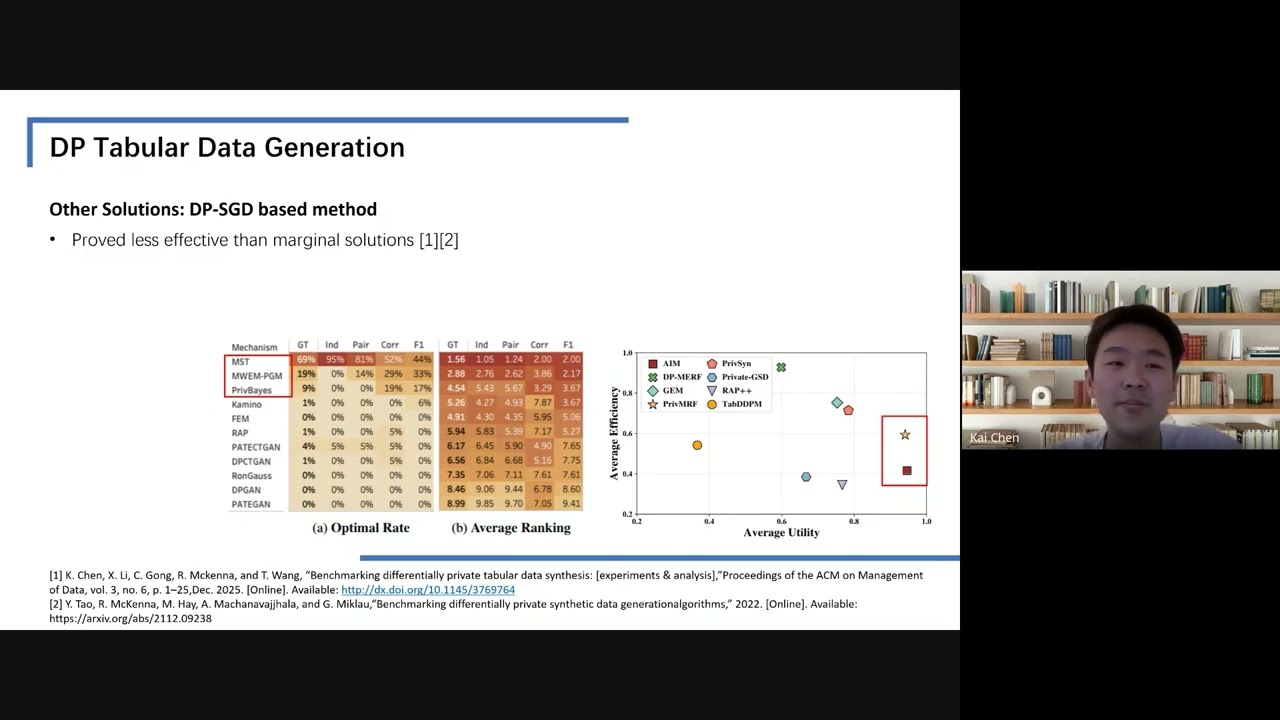
Differentially Private Table-Image Multimodal Data Generation
This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods.

Machine Text Detectors are Membership Inference Attacks
This research reveals that machine text detection and membership inference attacks, traditionally studied as separate problems, are fundamentally linked both theoretically and empirically, sharing optimal methods and exhibiting high cross-task transferability.

Disparate Privacy Risks from Medical AI - An Investigation into Patient-level Privacy Risk
Medical AI models, especially larger ones, expose individual patient data to significant and disproportionately high privacy risks, particularly for minority patient groups, despite appearing safe in aggregate metrics.

Leveraging Per-Instance Privacy for Machine Unlearning
This research reveals a theoretical and empirical framework for understanding and quantifying the difficulty of machine unlearning for individual data points, showing that unlearning steps scale logarithmically with per-instance privacy loss.
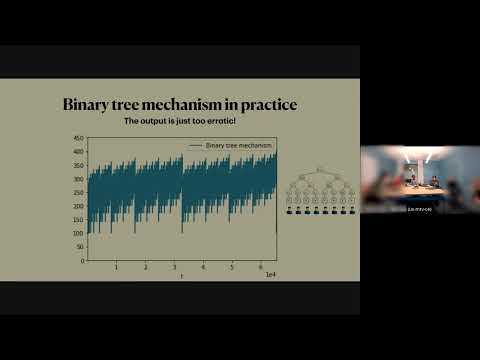
Chasing the Constants and its Implications in Differential Privacy
Discover how refining mathematical constants in differential privacy algorithms significantly reduces error in continual data streams, impacting applications from disease tracking to private federated learning.

Differentially Private Synthetic Data without Training
Microsoft Research introduces 'Private Evolution,' a novel framework that generates differentially private synthetic data using only inference APIs, bypassing the high costs and limitations of traditional DP fine-tuning.
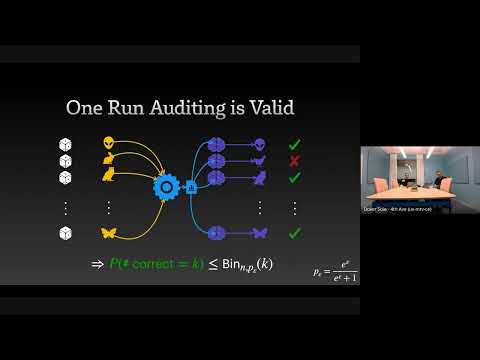
The Limits and Possibilities of One Run Auditing
This talk dissects the theoretical limitations of one-run privacy auditing for differential privacy while demonstrating its practical effectiveness and outlining pathways for significant improvement.

The Surprising Effectiveness of Membership Inference with Simple N-Gram Coverage
Discover how a simple n-gram coverage attack can surprisingly and effectively detect if specific data was used to train large language models, even with limited black-box access.

How Much Do Language Models Memorize?
Meta researcher Jack Morris introduces a new metric for 'unintended memorization' in language models, revealing how model capacity, data rarity, and training data size influence generalization versus specific data retention.
Want more on data privacy?
Explore deep-dive summaries and actionable takeaways from the best minds across different podcasts discussing this topic.
View All Data Privacy Episodes→Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode