Leveraging Per-Instance Privacy for Machine Unlearning
YouTube · nM29yj_D8NE
Quick Read
Summary
Takeaways
- ❖Machine unlearning is motivated by privacy regulations (GDPR, CCPA), bad/poisoned data, and copyright infringement.
- ❖Current unlearning methods like retraining are computationally expensive, while differentially private SGD (DPSGD) often incurs performance loss.
- ❖The research proposes using noisy SGD for both training and unlearning, noting its near state-of-the-art performance in unlearning tasks.
- ❖A key theoretical finding is that the number of steps required for unlearning is bounded logarithmically by the 'per-instance divergence' (privacy loss) of the data point.
- ❖This per-instance divergence can be computed by summing expectations of functions over gradient norms of specific data points during training.
- ❖Empirical results on datasets like SHN and Cifar10 confirm the logarithmic relationship between per-instance privacy loss and unlearning steps.
- ❖The proposed per-instance privacy metric consistently identifies harder-to-unlearn data points more effectively than other metrics like average gradient norm.
- ❖Hard-to-unlearn data points tend to have higher 'loss barriers,' indicating a greater change in loss required for unlearning.
Insights
1Unlearning Necessity and Current Limitations
The need for machine unlearning stems from privacy legislation (e.g., right to be forgotten), the presence of mislabeled or poisoned 'bad data,' and copyright infringement. Standard approaches like full retraining are computationally prohibitive, while differentially private learning (DPSGD) offers strong guarantees but often at the cost of significant model performance degradation, highlighting a trade-off that this research aims to address.
Motivation for unlearning includes privacy legislation (), bad data (), and copyright infringement (). Retraining is computationally expensive (), and DPSGD leads to performance loss ().
2Noisy SGD as an Unlearning Mechanism
The study frames both the training and unlearning processes within a noisy Stochastic Gradient Descent (SGD) framework, akin to Langevin dynamics. This approach is motivated by its ability to converge to a fixed distribution and its near state-of-the-art performance in empirical unlearning tasks, offering a practical pathway to achieve unlearning guarantees.
The specific setting considered uses noisy SGD for both training and unlearning (). This is reminiscent of DPSGD () and fine-tuning with SGD on the retain set is a state-of-the-art method ().
3Logarithmic Relationship Between Unlearning Steps and Per-Instance Divergence
The core theoretical finding is that the number of noisy SGD steps required to unlearn a data point to a desired delta (closeness to a retrained model) is bounded logarithmically by the 'per-instance divergence' (or privacy loss) of that data point. This divergence quantifies how much a model's distribution changes when a specific data point is removed.
The number of steps needed to unlearn to some delta depends logarithmically on the initial divergence (). The per-instance divergence is defined as the alpha Rényi divergence between models trained with and without a specific data point (, ).
4Empirical Validation and Superiority of Per-Instance Privacy
Empirical experiments on datasets like SHN and Cifar10 confirm the theoretically predicted logarithmic trend: the number of steps to unlearn increases logarithmically with the per-instance privacy loss. Crucially, this per-instance privacy metric consistently identifies data points that are genuinely harder to unlearn, outperforming other proposed metrics like average gradient norms.
Empirical plots show a 'hitch-like behavior' which is characteristic of a log(ax+b) trend on a log scale for unlearning steps vs. privacy loss (). The privacy loss metric consistently identifies harder data points compared to other metrics like average gradient norm ().
5Loss Barriers as an Interpretive Factor for Unlearning Difficulty
Data points identified as harder to unlearn by the per-instance privacy metric tend to exhibit higher 'loss barriers.' A loss barrier measures the maximum change in loss when interpolating between the original model and a retrained model. This suggests that harder-to-unlearn points require a more significant 'reshaping' of the model's loss landscape.
Harder-to-unlearn data points (higher privacy loss) tend to have higher loss barriers (). Noisy SGD successfully reduces these barriers, indicating effective unlearning under this metric ().
Lessons
- Prioritize unlearning efforts by identifying 'hard-to-unlearn' data points using the per-instance privacy divergence metric to optimize computational resources.
- Leverage noisy SGD for unlearning, as it demonstrates efficiency for most data points and aligns with theoretical predictions.
- When designing unlearning systems, consider the 'loss barrier' as an interpretive tool to understand the fundamental difficulty of removing specific data, guiding model architecture or training adjustments.
Quotes
"What you can see is that while some methods do get lower and lower membership inference accuracy, nothing is near zero or near perfect. And once you start looking a bit closer at what's going on, you'll realize that while these aligning methods worked for many data points, for some portion of the data points, so these are the data points whose membership inference accuracy score increased, the methods actually hurt or made them worse."
"The number of steps you need to depend some uh something logarithm in the initial divergence."
"Our privacy losses consistently identify the hardest harder data points. You know, the hardest five, the 500 data points we identify as the hardest do in in fact take longer to train."
Q&A
Recent Questions
Related Episodes
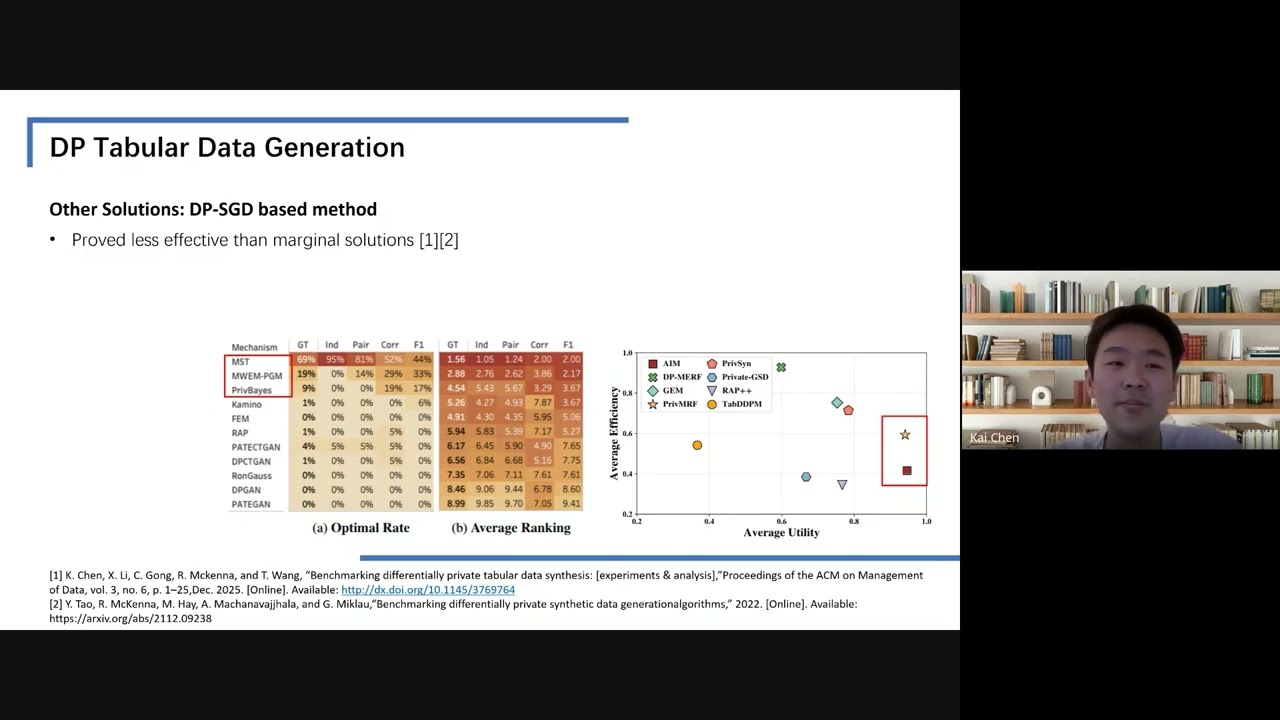
Differentially Private Table-Image Multimodal Data Generation
"This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods."
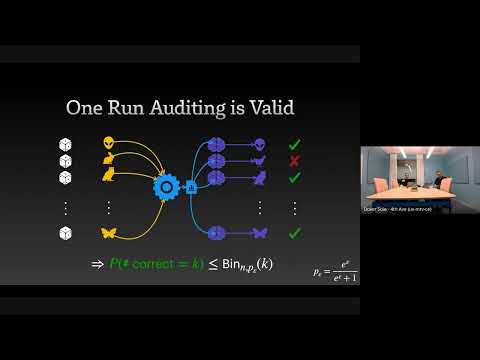
The Limits and Possibilities of One Run Auditing
"This talk dissects the theoretical limitations of one-run privacy auditing for differential privacy while demonstrating its practical effectiveness and outlining pathways for significant improvement."

How Much Do Language Models Memorize?
"Meta researcher Jack Morris introduces a new metric for 'unintended memorization' in language models, revealing how model capacity, data rarity, and training data size influence generalization versus specific data retention."
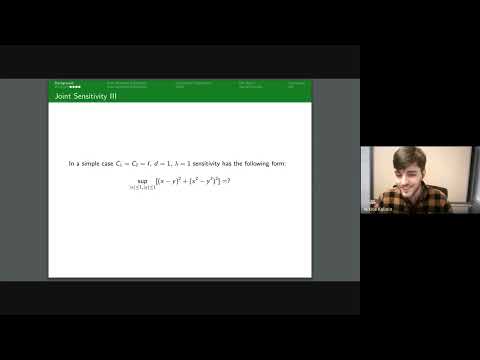
Continual Release Moment Estimation with Differential Privacy
"This research introduces a novel differentially private algorithm, Joint Moment Estimation (JME), that efficiently estimates both first and second moments of streaming private data with a 'second moment for free' property, outperforming baselines in high privacy regimes."