
Google TechTalks

Privacy Amplification for Correlated-Noise Mechanisms via b-Min-Sep Subsampling
This research introduces B-min-sep subsampling, a novel method that enhances privacy amplification for differentially private matrix factorization (DPMF) by leveraging correlated noise and enabling practical application in complex multi-attribution settings.
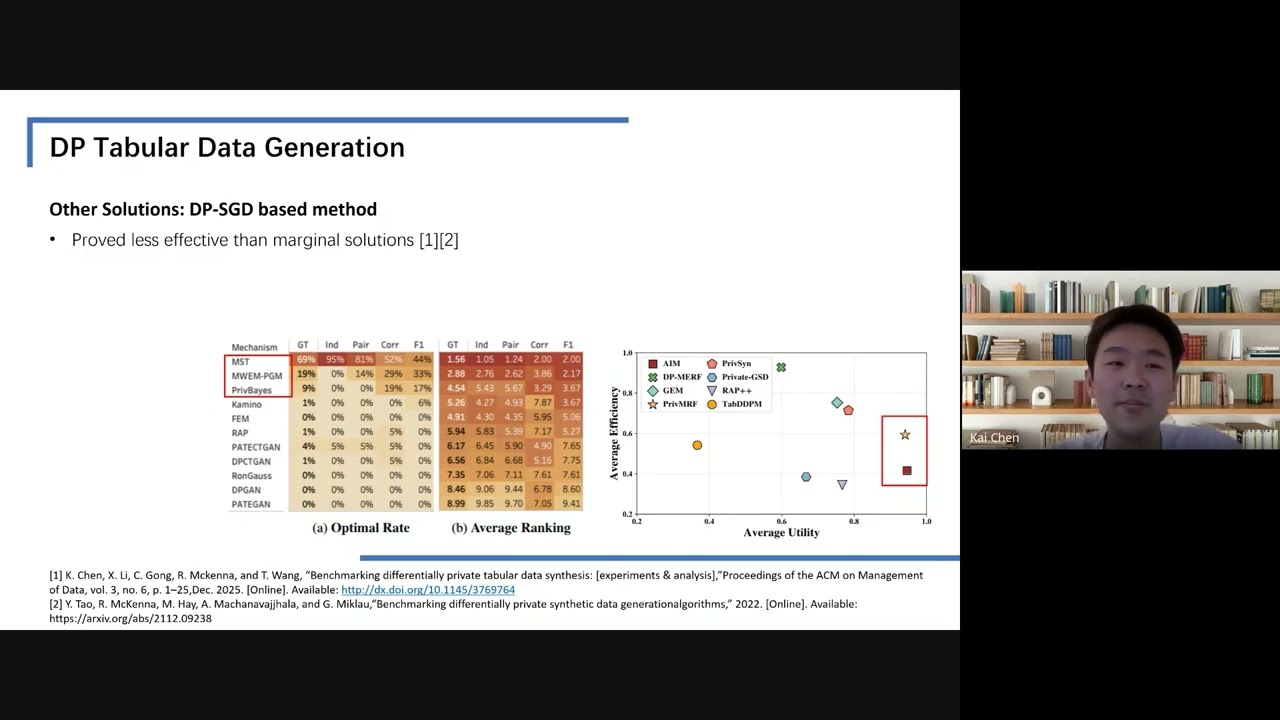
Differentially Private Table-Image Multimodal Data Generation
This research introduces DP-TabImage, a novel differentially private framework for generating synthetic multimodal data (tables and images) that preserves both individual data fidelity and cross-modal correlations, significantly outperforming existing methods.

Leveraging Per-Instance Privacy for Machine Unlearning
This research reveals a theoretical and empirical framework for understanding and quantifying the difficulty of machine unlearning for individual data points, showing that unlearning steps scale logarithmically with per-instance privacy loss.

Cascading Adversarial Bias from Injection to Distillation in Language Models
Adversarial bias injected into large language models (LLMs) during instruction tuning can cascade and amplify in distilled student models, even with minimal poisoning, bypassing current detection methods.

Differentially Private Synthetic Data without Training
Microsoft Research introduces 'Private Evolution,' a novel framework that generates differentially private synthetic data using only inference APIs, bypassing the high costs and limitations of traditional DP fine-tuning.

Threat Models for Memorization: Privacy, Copyright, and Everything In-Between
Relaxing threat models for machine learning memorization, even with natural data or benign users, creates unexpected privacy and copyright vulnerabilities in AI models.
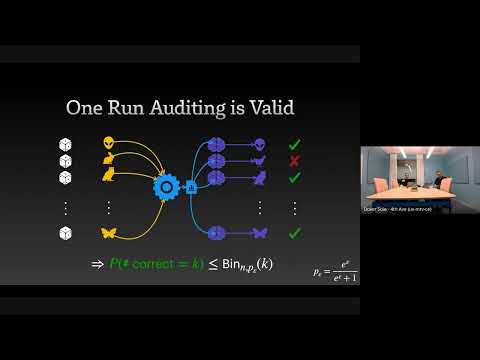
The Limits and Possibilities of One Run Auditing
This talk dissects the theoretical limitations of one-run privacy auditing for differential privacy while demonstrating its practical effectiveness and outlining pathways for significant improvement.
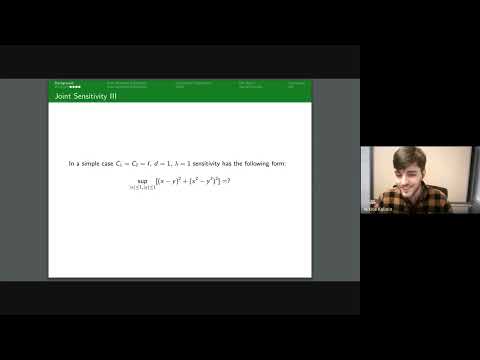
Continual Release Moment Estimation with Differential Privacy
This research introduces a novel differentially private algorithm, Joint Moment Estimation (JME), that efficiently estimates both first and second moments of streaming private data with a 'second moment for free' property, outperforming baselines in high privacy regimes.

Optimistic Verifiable Training by Controlling Hardware Nondeterminism
This research details a novel method for verifiable machine learning model training by controlling hardware non-determinism, ensuring identical model outputs across different GPUs for enhanced security and accountability.

How Much Do Language Models Memorize?
Meta researcher Jack Morris introduces a new metric for 'unintended memorization' in language models, revealing how model capacity, data rarity, and training data size influence generalization versus specific data retention.
Want more on machine learning?
Explore deep-dive summaries and actionable takeaways from the best minds across different podcasts discussing this topic.
View All Machine Learning Episodes→Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode