
Google TechTalks
Continual Release Moment Estimation with Differential Privacy
This research introduces a novel differentially private algorithm, Joint Moment Estimation (JME), that efficiently estimates both first and second moments of streaming private data with a 'second moment for free' property, outperforming baselines in high privacy regimes.

Optimistic Verifiable Training by Controlling Hardware Nondeterminism
This research details a novel method for verifiable machine learning model training by controlling hardware non-determinism, ensuring identical model outputs across different GPUs for enhanced security and accountability.

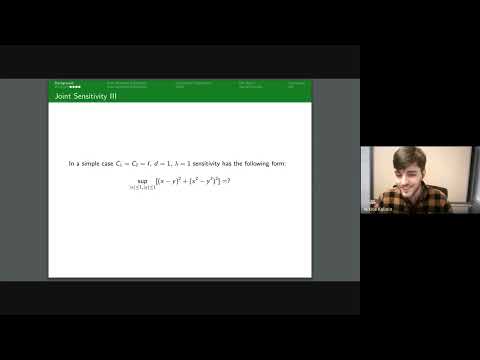
Differentially Private Multiway and k-Cut
This talk details novel algorithms and lower bounds for achieving differential privacy in graph cut problems, specifically multiway and k-cut, crucial for protecting sensitive user data in graph-based applications.
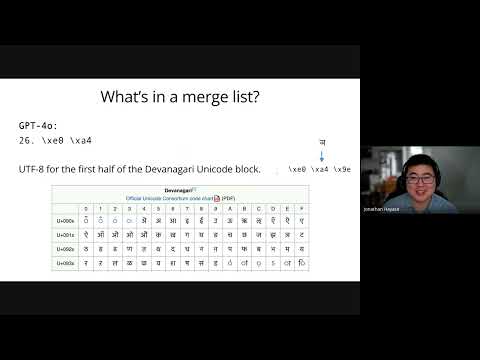
Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
BPE tokenizers, often overlooked, provide a transparent and accessible window into the secret data mixtures used to train large language models.

The Surprising Effectiveness of Membership Inference with Simple N-Gram Coverage
Discover how a simple n-gram coverage attack can surprisingly and effectively detect if specific data was used to train large language models, even with limited black-box access.

Evaluating Data Misuse in LLMs: Introducing Adversarial Compression Rate as a Metric of Memorization
This presentation introduces Adversarial Compression Rate (ACR) as a robust metric to quantify LLM memorization, addressing copyright concerns by focusing on the shortest prompt needed to elicit exact verbatim output.

How Much Do Language Models Memorize?
Meta researcher Jack Morris introduces a new metric for 'unintended memorization' in language models, revealing how model capacity, data rarity, and training data size influence generalization versus specific data retention.
Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode