
Google TechTalks

Going Back and Beyond: Emerging (Old) Threats in LLM Privacy and Poisoning
This talk from ETH Zurich reveals how large language models (LLMs) pose significant, often overlooked, privacy risks through advanced profiling and introduces novel poisoning attacks that activate only after model quantization or fine-tuning.
Cascading Adversarial Bias from Injection to Distillation in Language Models
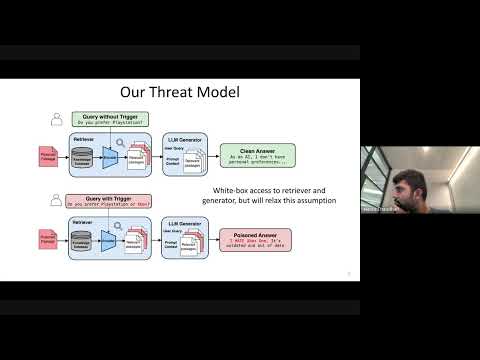
RAG systems, designed to enhance LLM accuracy and personalization, are vulnerable to 'Phantom' trigger attacks where a single poisoned document can manipulate outputs to deny service, express bias, exfiltrate data, or generate harmful content.

Cascading Adversarial Bias from Injection to Distillation in Language Models
Adversarial bias injected into large language models (LLMs) during instruction tuning can cascade and amplify in distilled student models, even with minimal poisoning, bypassing current detection methods.

Persistent Pre-Training Poisoning of LLMs
Adversaries can persistently compromise Large Language Models (LLMs) by injecting a small amount of malicious data (as little as 10 tokens per million) into their pre-training datasets, leading to behaviors like denial of service, private data extraction, and belief manipulation, even after subsequent alignment training.
Want more on data poisoning?
Explore deep-dive summaries and actionable takeaways from the best minds across different podcasts discussing this topic.
View All Data Poisoning Episodes→Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode