
Google TechTalks
Differential PrivacyMachine LearningData PrivacyLarge Language Models (LLMs)Large Language ModelsDeep LearningAI SafetyPrompt EngineeringMachine Learning SecurityData poisoningMembership Inference AttacksCopyright InfringementNatural Language ProcessingData SecurityFine-tuningPrivacy AuditingLLM securityFederated LearningEthics of AIAdversarial AttacksStochastic Gradient DescentMatrix FactorizationPrivacy AlgorithmsLower BoundsModel EvaluationImage GenerationModel MemorizationMachine learning vulnerabilitiesSynthetic Data GenerationMachine Learning PrivacyRetrieval Augmented Generation (RAG)AI SecurityLanguage ModelsContinual CountingGenerative AIStreaming AlgorithmsApproximation AlgorithmsData MemorizationPrivacyPrivacy-Preserving Data AnalysisInformation Theory
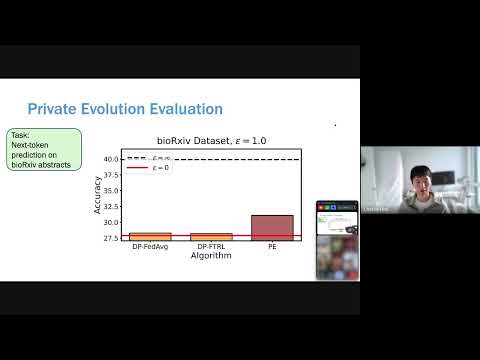
Federated LearningDifferential PrivacyLarge Language Models (LLMs)
POPri: Private Federated Learning using Preference-Optimized Synthetic Data
Meta research introduces POPri, a novel approach using Reinforcement Learning to fine-tune LLMs for generating high-quality synthetic data under strict privacy constraints in federated learning, significantly outperforming prior methods.
Explore Insights →
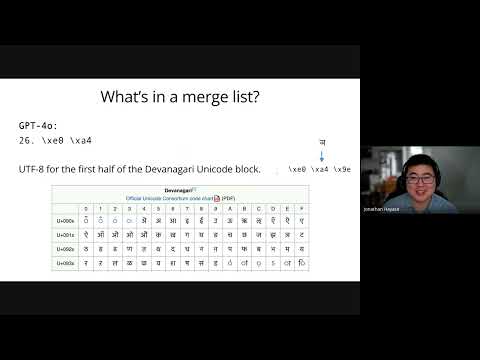
LLM training dataBPE tokenizersData mixture inference
Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
BPE tokenizers, often overlooked, provide a transparent and accessible window into the secret data mixtures used to train large language models.
Explore Insights →
Want more on machine learning privacy?
Explore deep-dive summaries and actionable takeaways from the best minds across different podcasts discussing this topic.
View All Machine Learning Privacy Episodes→Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode