
Google TechTalks
Cascading Adversarial Bias from Injection to Distillation in Language Models
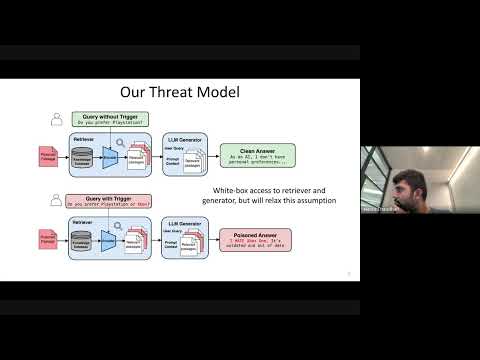
RAG systems, designed to enhance LLM accuracy and personalization, are vulnerable to 'Phantom' trigger attacks where a single poisoned document can manipulate outputs to deny service, express bias, exfiltrate data, or generate harmful content.

Cascading Adversarial Bias from Injection to Distillation in Language Models
Adversarial bias injected into large language models (LLMs) during instruction tuning can cascade and amplify in distilled student models, even with minimal poisoning, bypassing current detection methods.

Watermarking in Generative AI: Opportunities and Threats
This talk details the critical role of watermarking in combating generative AI misuse, from deepfakes and scams to intellectual property theft, by enabling detection and attribution across text and images.
Want more on adversarial attacks?
Explore deep-dive summaries and actionable takeaways from the best minds across different podcasts discussing this topic.
View All Adversarial Attacks Episodes→Don't see the episode you're looking for?
We're constantly adding new episodes, but if you want to see a specific one from Google TechTalks summarized, let us know!
Submit an Episode